Large language models (LLMs) have become increasingly popular in natural language processing tasks due to their ability to generate human-like text. However, these pre-trained models may not always meet the specific requirements of every application or domain. This is where LLM fine-tuning comes into play, offering a way to customize these models to better suit individual needs. By understanding the process of LLM fine-tuning, one can harness the power of these models and tailor them to their unique requirements, whether it be for chatbots, translation systems, or other language-related applications. In this article, we will delve into the intricacies of LLM fine-tuning and explore how it enables us to optimize large language models for specific tasks, opening up a world of possibilities for natural language processing practitioners.
As we stand in September 2023, the landscape of Large Language Models (LLMs) is still witnessing the rise of models including Alpaca, Falcon, Llama 2, GPT-4, and many others.
You are viewing: Understanding LLM Fine-Tuning: Tailoring Large Language Models to Your Unique Requirements
An important aspect of leveraging the potential of these LLMs lies in the fine-tuning process, a strategy that allows for the customization of pre-trained models to cater to specific tasks with precision. It is through this fine-tuning that these models can truly align with individualized requirements, offering solutions that are both innovative and tailored to unique needs.
However, it is essential to note that not all fine-tuning avenues are created equal. For instance, accessing the fine-tuning capabilities of the GPT-4 comes at a premium, requiring a paid subscription that is relatively more expensive compared to other options available in the market. On the other hand, the open-source domain is bustling with alternatives that offer a more accessible pathway to harnessing the power of large language models. These open-source options democratize access to advanced AI technology, fostering innovation and inclusivity in the rapidly evolving AI landscape.

Hugging Face – Open LLM Leaderboard
Why is LLM fine-tuning important?
LLM fine-tuning is more than a technical enhancement; it is a crucial aspect of LLM model development that allows for a more specific and refined application in various tasks. Fine-tuning adjusts the pre-trained models to better suit specific datasets, enhancing their performance in particular tasks and ensuring a more targeted application. It brings forth the remarkable ability of LLMs to adapt to new data, showcasing flexibility that is vital in the ever-growing interest in AI applications.
Fine-tuning large language models opens up a lot of opportunities, allowing them to excel in specific tasks ranging from sentiment analysis to medical literature reviews. By tuning the base model to a specific use case, we unlock new possibilities, enhancing the model’s efficiency and accuracy. Moreover, it facilitates a more economical utilization of system resources, as fine-tuning requires less computational power compared to training a model from scratch.
As we go deeper into this guide, we will discuss the intricacies of LLM fine-tuning, giving you a comprehensive overview that is based on the latest advancements and best practices in the field.
Instruction-Based Fine-Tuning
The fine-tuning phase in the Generative AI lifecycle, illustrated in the figure below is characterized by the integration of instruction inputs and outputs, coupled with examples of step-by-step reasoning. This approach facilitates the model in generating responses that are not only relevant but also precisely aligned with the specific instructions fed into it. It is during this phase that the pre-trained models are adapted to solve distinct tasks and use cases, utilizing personalized datasets to enhance their functionality.

Generative AI Lifecycle – Fine Tuning
Single-Task Fine-Tuning
Single-task fine-tuning focuses on honing the model’s expertise in a specific task, such as summarization. This approach is particularly beneficial in optimizing workflows involving substantial documents or conversation threads, including legal documents and customer support tickets. Remarkably, this fine-tuning can achieve significant performance enhancements with a relatively small set of examples, ranging from 500 to 1000, a contrast to the billions of tokens utilized in the pre-training phase.

Single-Task Fine Tuning Example Illustration
Foundations of LLM Fine-Tuning LLM: Transformer Architecture and Beyond
The journey of understanding LLM fine-tuning begins with a grasp of the foundational elements that constitute LLMs. At the heart of these models lies the transformer architecture, a neural network that leverages self-attention mechanisms to prioritize the context of words over their proximity in a sentence. This innovative approach facilitates a deeper understanding of distant relationships between tokens in the input.
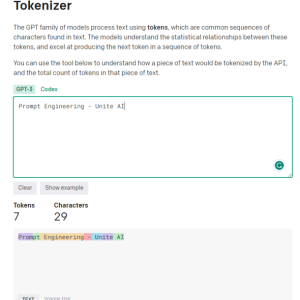
As we navigate through the intricacies of transformers, we encounter a multi-step process that begins with the encoder. This initial phase involves tokenizing the input and creating embedding vectors that represent the input and its position in the sentence. The subsequent stages involve a series of calculations using matrices known as Query, Value, and Key, culminating in a self-attention score that dictates the focus on different parts of the sentence and various tokens.

Transformer Architecture
Fine-tuning stands as a critical phase in the development of LLMs, a process that entails making subtle adjustments to achieve more desirable outputs. This stage, while essential, presents a set of challenges, including the computational and storage demands of handling a vast number of parameters. Parameter Efficient Fine-Tuning (PEFT) offers techniques to reduce the number of parameters to be fine-tuned, thereby simplifying the training process.
LLM Pre-Training: Establishing a Strong Base
See more : 20 Best ChatGPT Prompts for Social Media (November 2023)
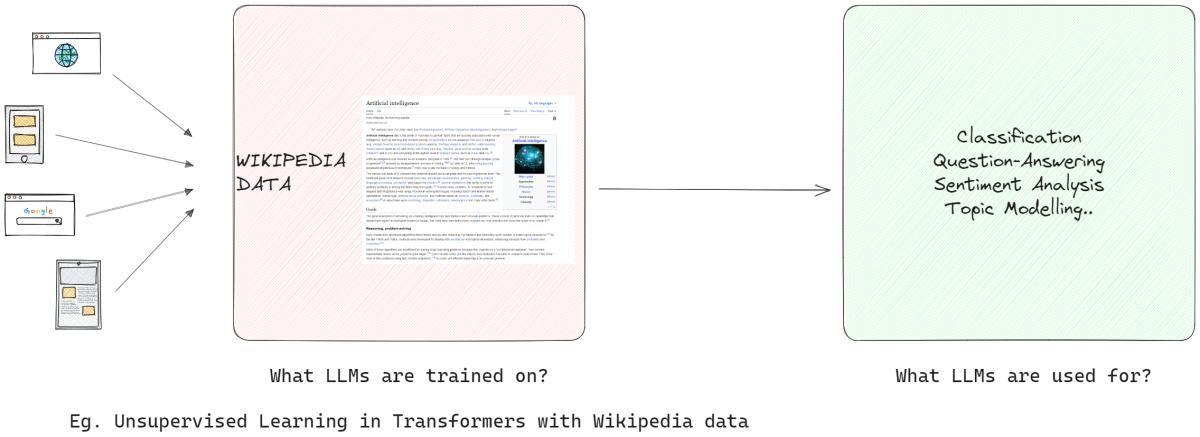
In the initial stages of LLM development, pre-training takes center stage, utilizing over-parameterized transformers as the foundational architecture. This process involves modeling natural language in various manners such as bidirectional, autoregressive, or sequence-to-sequence on large-scale unsupervised corpora. The objective here is to create a base that can be fine-tuned later for specific downstream tasks through the introduction of task-specific objectives.

Pre-training, Fine-Tuning
A noteworthy trend in this sphere is the inevitable increase in the scale of pre-trained LLMs, measured by the number of parameters. Empirical data consistently shows that larger models coupled with more data almost always yield better performance. For instance, the GPT-3, with its 175 billion parameters, has set a benchmark in generating high-quality natural language and performing a wide array of zero-shot tasks proficiently.
Fine-Tuning: The Path to Model Adaptation
Following the pre-training, the LLM undergoes fine-tuning to adapt to specific tasks. Despite the promising performance shown by in-context learning in pre-trained LLMs such as GPT-3, fine-tuning remains superior in task-specific settings. However, the prevalent approach of full parameter fine-tuning presents challenges, including high computational and memory demands, especially when dealing with large-scale models.
For large language models with over a billion parameters, efficient management of GPU RAM is pivotal. A single model parameter at full 32-bit precision necessitates 4 bytes of space, translating to a requirement of 4GB of GPU RAM just to load a 1 billion parameter model. The actual training process demands even more memory to accommodate various components including optimizer states and gradients, potentially requiring up to 80GB of GPU RAM for a model of this scale.
To navigate the limitations of GPU RAM, quantization is used which is a technique that reduces the precision of model parameters, thereby decreasing memory requirements. For instance, altering the precision from 32-bit to 16-bit can halve the memory needed for both loading and training the model. Later on in this article. we will learn about Qlora which uses the quantization concept for tuning.

LLM GPU Memory requirement wrt. number of parameters and precision
Exploring the Categories of PEFT Methods

Parameter-efficient fine-tuning methods
In the process of fully fine-tuning Large Language Models, it is important to have a computational setup that can efficiently handle not just the substantial model weights, which for the most advanced models are now reaching sizes in the hundreds of gigabytes, but also manage a series of other critical elements. These include the allocation of memory for optimizer states, managing gradients, forward activations, and facilitating temporary memory during various stages of the training procedure.
Additive Method
This type of tuning can augment the pre-trained model with additional parameters or layers, focusing on training only the newly added parameters. Despite increasing the parameter count, these methods enhance training time and space efficiency. The additive method is further divided into sub-categories:
- Adapters: Incorporating small fully connected networks post transformer sub-layers, with notable examples being AdaMix, KronA, and Compactor.
- Soft Prompts: Fine-tuning a segment of the model’s input embeddings through gradient descent, with IPT, prefix-tuning, and WARP being prominent examples.
- Other Additive Approaches: Include techniques like LeTS, AttentionFusion, and Ladder-Side Tuning.
Selective Method
Selective PEFTs fine-tune a limited number of top layers based on layer type and internal model structure. This category includes methods like BitFit and LN tuning, which focus on tuning specific elements such as model biases or particular rows.
Reparametrization-based Method
These methods utilize low-rank representations to reduce the number of trainable parameters, with the most renowned being Low-Rank Adaptation or LoRA. This method leverages a simple low-rank matrix decomposition to parameterize the weight update, demonstrating effective fine-tuning in low-rank subspaces.
1) LoRA (Low-Rank Adaptation)
LoRA emerged as a groundbreaking PEFT technique, introduced in a paper by Edward J. Hu and others in 2021. It operates within the reparameterization category, freezing the original weights of the LLM and integrating new trainable low-rank matrices into each layer of the Transformer architecture. This approach not only curtails the number of trainable parameters but also diminishes the training time and computational resources necessitated, thereby presenting a more efficient alternative to full fine-tuning.
To comprehend the mechanics of LoRA, one must revisit the transformer architecture where the input prompt undergoes tokenization and conversion into embedding vectors. These vectors traverse through the encoder and/or decoder segments of the transformer, encountering self-attention and feed-forward networks whose weights are pre-trained.
LoRA uses the concept of Singular Value Decomposition (SVD). Essentially, SVD dissects a matrix into three distinct matrices, one of which is a diagonal matrix housing singular values. These singular values are pivotal as they gauge the significance of different dimensions in the matrices, with larger values indicating higher importance and smaller ones denoting lesser significance.

Singular Value Decomposition (SVD) of m × n Matrix
This approach allows LoRA to maintain the essential characteristics of the data while reducing the dimensionality, hence optimizing the fine-tuning process.
See more : 10 Best ChatGPT Prompts for HR Professionals
LoRA intervenes in this process, freezing all original model parameters and introducing a pair of “rank decomposition matrices” alongside the original weights. These smaller matrices, denoted as A and B, undergo training through supervised learning.

LORA LLM Illustration
The pivotal element in this strategy is the parameter called rank (‘r’), which dictates the size of the low-rank matrices. A meticulous selection of ‘r’ can yield impressive results, even with a smaller value, thereby creating a low-rank matrix with fewer parameters to train. This strategy has been effectively implemented using open-source libraries such as HuggingFace Transformers, facilitating LoRA fine-tuning for various tasks with remarkable efficiency.
2) QLoRA: Taking LoRA Efficiency Higher
Building on the foundation laid by LoRA, QLoRA further minimizes memory requirements. Introduced by Tim Dettmers and others in 2023, it combines low-rank adaptation with quantization, employing a 4-bit quantization format termed NormalFloat or nf4. Quantization is essentially a process that transitions data from a higher informational representation to one with less information. This approach maintains the efficacy of 16-bit fine-tuning methods, dequantizing the 4-bit weights to 16-bits as necessitated during computational processes.

Comparing finetuning methods: QLORA enhances LoRA with 4-bit precision quantization and paged optimizers for memory spike management
QLoRA leverages NumericFloat4 (nf4), targeting every layer in the transformer architecture, and introduces the concept of double quantization to further shrink the memory footprint required for fine-tuning. This is achieved by performing quantization on the already quantized constants, a strategy that averts typical gradient checkpointing memory spikes through the utilization of paged optimizers and unified memory management.
Guanaco, which is a QLORA-tuned ensemble, sets a benchmark in open-source chatbot solutions. Its performance, validated through systematic human and automated assessments, underscores its dominance and efficiency in the field.
The 65B and 33B versions of Guanaco, fine-tuned utilizing a modified version of the OASST1 dataset, emerge as formidable contenders to renowned models like ChatGPT and even GPT-4.
Fine-tuning using Reinforcement Learning from Human Feedback
Reinforcement Learning from Human Feedback (RLHF) comes into play when fine-tuning pre-trained language models to align more closely with human values. This concept was introduced by Open AI in 2017 laying the foundation for enhanced document summarization and the development of InstructGPT.
At the core of RLHF is the reinforcement learning paradigm, a type of machine learning technique where an agent learns how to behave in an environment by performing actions and receiving rewards. It’s a continuous loop of action and feedback, where the agent is incentivized to make choices that will yield the highest reward.
Translating this to the realm of language models, the agent is the model itself, operating within the environment of a given context window and making decisions based on the state, which is defined by the current tokens in the context window. The “action space” encompasses all potential tokens the model can choose from, with the goal being to select the token that aligns most closely with human preferences.
The RLHF process leverages human feedback extensively, utilizing it to train a reward model. This model plays a crucial role in guiding the pre-trained model during the fine-tuning process, encouraging it to generate outputs that are more aligned with human values. It is a dynamic and iterative process, where the model learns through a series of “rollouts,” a term used to describe the sequence of states and actions leading to a reward in the context of language generation.

Instruct-GPT
One of the remarkable potentials of RLHF is its ability to foster personalization in AI assistants, tailoring them to resonate with individual users’ preferences, be it their sense of humor or daily routines. It opens up avenues for creating AI systems that are not just technically proficient but also emotionally intelligent, capable of understanding and responding to nuances in human communication.
However, it is essential to note that RLHF is not a foolproof solution. The models are still susceptible to generating undesirable outputs, a reflection of the vast and often unregulated and biased data they are trained on.
Conclusion
The fine-tuning process, a critical step in leveraging the full potential of LLMs such as Alpaca, Falcon, and GPT-4, has become more refined and focused, offering tailored solutions to a wide array of tasks.
We have seen single-task fine-tuning, which specializes in models in particular roles, and Parameter-Efficient Fine-Tuning (PEFT) methods including LoRA and QLoRA, which aim to make the training process more efficient and cost-effective. These developments are opening doors to high-level AI functionalities for a broader audience.
Furthermore, the introduction of Reinforcement Learning from Human Feedback (RLHF) by Open AI is a step towards creating AI systems that understand and align more closely with human values and preferences, setting the stage for AI assistants that are not only smart but also sensitive to individual user’s needs. Both RLHF and PEFT work in synergy to enhance the functionality and efficiency of Large Language Models.
As businesses, enterprises, and individuals look to integrate these fine-tuned LLMs into their operations, they are essentially welcoming a future where AI is more than a tool; it is a partner that understands and adapts to human contexts, offering solutions that are innovative and personalized.
That concludes the article: Understanding LLM Fine-Tuning: Tailoring Large Language Models to Your Unique Requirements
I hope this article has provided you with valuable knowledge. If you find it useful, feel free to leave a comment and recommend our website!
Click here to read other interesting articles: AI
Source: techfuzzy.com
#Understanding #LLM #FineTuning #Tailoring #Large #Language #Models #Unique #Requirements
Source: https://techfuzzy.com
Category: Prompt Engineering